

Forecasting Authoritarian and Sovereign Power uses of Large Language Models
What will the Chinese Communist Party do with a Large Language Model?

In 1933, the Nazi propagandist, Joseph Goebbels ordered the production of the Volksempfänger. It was a cheap, mass produced radio that allowed Nazi propaganda to be broadcast to poor German families. The slogan was “Every national comrade a radio listener.” It listed cities rather than frequencies to make it harder to find non-approved stations. Listening to contraband stations was criminalized and eventually became a capital crime. Goebbels later said, “It would not have been possible for us to take power or to use it in the ways we have without the radio...It is no exaggeration to say that the German revolution, at least in the form it took, would have been impossible without the airplane and the radio.”
A lot of the debate about ChatGPT has been around what it thinks about pronouns, or race, or all the other battle lines of the 2023 American Culture War. But ChatGPT is just one instantiation of a Large Language Model (LLM) and LLMs are going to be with us for the rest of our lives. It won’t just be American corporations that produce them. Other governments will make them. Some of those governments will be peaceful democracies and some will be dictatorships. I think the main question is what would Joseph Goebbels have done if he’d had an LLM instead of a radio?
But before I discuss that question, I want to make some forecasts about the authoritarian and sovereign power uses of LLMs:
A 70% probability that by the end of 2024 you’ll see at least one country create a nationalized, sovereign LLM and legally mandate it’s usage for censorship / propaganda reasons. They’ll need to get LLM hallucinations under control, but I discuss the technical reasons below why I’m optimistic that progress will be made for that.
A 50% probability that by the end of 2025 at least three countries will produce sovereign LLMs. Even if hallucinations aren’t perfectly under control, there are still going to be other economic benefits.
A 10% probability, that by the end of 2026, you’ll see one country cutoff another country from access to their LLM as part of economic sanctions.
My predictions are dependent on three main assumptions:
LLM hallucinations will be significantly reduced in the next year.
The barrier to entry will increase over next year.
The economic utility will dramatically increase over the next few years.
Any evidence that challenges these assumptions will make me lower my forecasts. Let me know in the comments if you think my forecasts are off.
World leaders have already expressed interest in AI — Putin said that whoever becomes the leader in AI “will become the ruler of the world.” However, I want to focus specifically on LLMs. China is cracking down on ChatGPT because it is not ideologically consistent with party propaganda but still investing billions in it’s own AI. Tony Blair is arguing that Britain needs its own sovereign LLM for economic security.
Love Bots and Decentralized Propaganda
In my mind, there have been three main types of communication in human history: one-to-one (pre-Gutenberg), then one-to-many (mass media), and then many-to-many (social media). First, prior to the printing press, communication was largely done on a one-to-one basis. Most people were illiterate, so messages were largely communicated from person to person. At the most, an individual person could communicate with a large crowd.
Then there was a gradual transition to mass communication where in the 1800’s literacy rates skyrocketed, mass printing became cheaper, and messages were transmitted to thousands, or tens of thousands of people at a time through a newspaper. This peaked with the radio and broadcast television in the late twentieth century. Let’s call this the one-to-many mode of communication. What’s important to note about this type of communication is that the people listening cannot talk back to the broadcasters and cannot broadcast themselves.
Finally, there was a very rapid transition to many-to-many communication, where news is primarily transmitted through social media. In this configuration the listeners can talk back and broadcast their own messages.
The Nazi’s were the first to exploit one-to-many (mass media broadcasting) for propaganda purposes. Mostly, the radios broadcast entertainment. Propaganda was a small part of what the nationalized broadcast company produced. The radios were also designed with an art deco cabinet. The strategy was simple: Make it fun. Make it beautiful. Make it cheap.

At the risk of being wildly speculative, I wonder what would happen if an authoritarian government deployed “love bots” that lonely people could talk to and fall in love with, but the bots all followed party propaganda. In the 2013 film, Her, Joaquin Phoenix’s character falls in love with an virtual assistant. What if the virtual assistant was provided by the governement and pushed regime narratives? Just like with the Nazi radios, it would mostly be entertainment, but only rarely switch to propaganda.
During the Nuremberg Trials, Hitler’s Minister for War production said:
Hitler's dictatorship differed in one fundamental point from all its predecessors in history. His was the first dictatorship in the present period of modern technical development, a dictatorship which made the complete use of all technical means for domination of its own country. Through technical devices like the radio and loudspeaker, 80 million people were deprived of independent thought.
Goebbels emphasized this was accomplished through centralization: “the result of the tight centralization, the strong reporting, and the up-to-date nature of the German radio…Above all it is necessary to clearly centralize all radio activities, to place spiritual tasks ahead of technical ones…to provide a clear worldview.” But in a social media ecosystem, propaganda is decentralized. How could someone do this in a decentralized system? I think that there are three main strategies for using LLMs for propaganda and censorship:
Social media bots for propaganda
Replacing search engines with LLMs for controlling information
Automating censorship of social media
In George Orwell’s novel, 1984, the main character, Winston, rewrites government bulletins and newspapers to keep them up to date with the current propaganda. It’s a system where the party members get their news directly from a centralized source. The party rewrites historical facts and claims to have invented the helicopter and the airplane. But in a social media system, people get their news from decentralized sources. What would Winston’s job be in an authoritarian regime that has social media (like China and Russia) and uses an LLM to enforce party propaganda? He could handcraft a few tweets about a narrative and then send them out for twenty different bot accounts. The bot account would continue on autopilot continuing the conversation. If the LLM is using a Toolformer approach where it makes an API call to a copy of Wikipedia to search for information, then he could update the internal Wikipedia that it uses. Winston’s could also entail doing some RLHF (Reinforcement Learning with Human Feedback) to update the response of the bot to certain narratives. You could do some prompt modification to give each bot distinct personalities.
The challenge with creating a bot army like this is that the largest account on social networks are always celebrities with large real life followings. So in order to push a narrative in a certain way, an authoritarian government would have to really saturate the network with bots. They could also just amplify and retweet the messages from real human celebrities when they say things that are consistent with the party-approved propaganda.
A government could now in theory deploy a centralized, party approved search engine that contains an up to date narrative. It could rewrite historical facts to claim the CCP invented the helicopter and the airplane. Kim Jong Un could encode that he learned to drive at age three or that he doesn’t need to poop or that he can speak to dolphins. Replacing search engines with LLMs would mean that there is an official source of truth. This search engine would become the Winston in Orwell’s novel. Even if armies of chatbots on social media aren’t useful, integrating a search engine with a LLM (in exactly the way that Bing has done) could be a very useful way to control information.
There’s both propaganda and then there’s censorship. In a social media ecosystem the United States has had a number of moral panics around disinformation, like with anti-vaxxers or RussiaGate, and the censorship has been done manually through humans reading through tweets. Instead, an LLM could automate this process.
LLMs and National Economic Power
In terms of my forecasts, there is another major reason why countries would want to create a nationalized LLM, and that’s economic power.
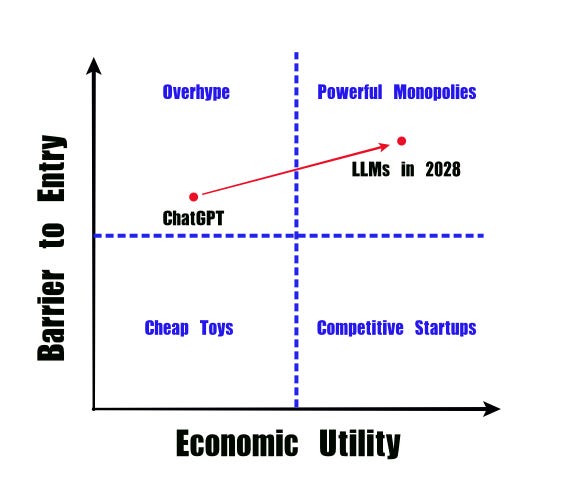
Over time, as LLMs improve, they will shift to the righthand side of this chart. The open question is whether they stay towards the top (expensive) or shift to the bottom (accessible). I think they’ll actually increasingly move towards the top. Most of the knowledge to make the best models is open source, but the datasets are not. As more people use these models, they’ll only gain more data, the models will improve, and there will be a positive feedback loop where the most popular models get better and better and only more popular.
The tech trend over the past 15 years has been towards services, where instead of buying an app to download, you pay for a monthly subscription and can access it via the web. Cloud computing made infrastructure a service and this has become a foundational tool for almost every tech company. When Amazon decided that Parler, the free speech social media platform, was allowing ideologically inconvenient posts they kicked them off their cloud services and the company never recovered. If intelligence becomes a service, and it becomes a foundational tool for other companies, then they could similarly cutoff access to their LLM service.
Imagine the most extreme case, where we end up in the upper right corner. In this situation, the best LLMs would require the same cost as the Apollo space program and you’d see only nation states with the resources to build it. But because you’re at the far right side of the spectrum, it would also have massive economic benefits. If one country came up with a powerful LLM, they could use it as leverage. A corporation or country that controls a powerful LLM behind an API could have something akin to a oil pipeline. They could threaten to cutoff access to another country, like Russia threatening to cutoff access to oil and natural gas to the EU. Or a corporation with a powerful LLM could cut off an entire country from their tool as leverage to influence tax policies.
Building Large Language Models
Understanding the main steps involved in training a LLM will explain why the barrier to entry will rise in the next year. I covered in an earlier post the geometry of an LLM, but I didn’t cover the high level steps on how to produce one.
There are four main steps to training a chatbot LLM:
Step 1 (Pretraining): You train a model to predict the next word in a sequence. These datasets are open source and have over a trillion tokens. This creates a general-purpose LLM that can do anything from write poetry, to code, to newspaper articles.
Step 2 (Finetuning): The model from step 1 is trained on question / answer formats to fine-tune it to produce this style of conversation. These datasets are proprietary. This step creates a LLM that is specialized as a chatbot rather than the more general purpose model from step 1. This fine-tuned model is then forked and used to produce two different models in steps 3 and 4.
Step 3 (Reward Model): You take the fine-tuned model and then use it to output a value instead of a word. Humans take examples of questions and answers and then rate the quality of the answer. They downrate answers that are offensive or do not ideologically conform. This is called the reward model.
Step 4 (RLHF): You take the fine-tuned model from step 2 and then have it answer questions and the reward model from step 3 scores the answers. The reward model decides if the answer was good or not and that’s how the model from step 2 is further refined to be ideologically tolerant. This further refines the chatbot from step 2 to becoming a chatbot that ideologically conforms.
Note that the dataset from step 1 is open source but huge. This creates millions of dollars in compute costs. Step 2 and 3 use proprietary datasets that are difficult to reproduce. Each of these 3 steps creates a barrier to entry.
I might be susceptible to recency bias here, but there are two very recent papers that I think have a ton of potential for LLMs. One is Toolformer and the other is Multimodal LLMs. Multimodal LLMs put text, images, video, audio all into one big model. If this is effective, it could be a major step towards AGI, and these different inputs could help stabilize each other and reduce hallucinations. The Multimodal LLMs would mean that the dataset and compute required will both increase. Likely the number of weights required as well.
Toolformer allows the Transformer to make calls to an API, like a calculator or a calendar or a Wikipedia search. There are no changes to the model, just the dataset that it’s trained on. It learns to output something like “In 1865 Abraham Lincoln was killed by [WikiSearch(‘Abraham Lincoln’)”. Using tools is what separates humans from other animals, and the fact that LLMs are already smart enough to do this, without any model changes is notable in it’s own right. The Toolformer actually shrinks the number of weights required to achieve a benchmark, however, it likely will improve performance for the largest LLMs as well. I think making Toolformer highly useful will require more datasets. Generating these datasets will be either computationally or financially expensive.
Everything seems to be pointing in the direction of raising the barrier to entry, not lowering it. The architecture from the original Transformer in 2017 to GPT-3 has actually barely changed. The only real change to the model between the original GPT and GPT-3 was swapping the LayerNorm from after the Attention block to before the Attention block (the pre-norm formulation as it’s called). The main thing has been increasing the size of the model and the size of the dataset. It’s turned into a massive scaling race. Multimodal LLMs are just going to exacerbate this.
As we move up and to the right in the chart above we’ll see LLMs become more powerful and more expensive. Countries will begin to see access to LLMs as a matter of economic security just as we see oil today. Additionally, authoritarian countries are going to see it as a means of ideological control. And even in the United States, Matt Taibbi’s work on the Twitter Files has shown that the US government is actively censoring social media. LLMs will only allow them to automate this process.
There are some good reasons why I might be wrong. Laion and the Eleuther collective are producing state of the art models with very limited resources. Also, Facebook’s LLaMA was leaked from their lab and is now available on BitTorrent. The question is whether these open source groups can produce state of the art models, or nearly SOA models, and whether that small edge makes a difference. Also, whether they can be deployed cheaply, at scale.
Let me know what you think the forecasts should be.
China and India are facing a gender crisis. There is a surplus of men that are doomed to be single. I could see the CCP and the Indian government pushing lovebots onto these lonely men. After all, large groups of single men have rarely ended up well for governments.
The West is also facing a similar crisis. More women graduate from college than men, and they don’t want men without an education. A lot of non-college-educated men will end up single and the government may placate them with lovebots. It’s a disturbing thought but may one day be a reality.
Liam, under what circumstances would you consider being interviewed on or contributing this article for an online HR magazine I am editing?
if interested email me petar@gapjumpers.me