

Geometric Intuition for why ChatGPT is NOT Sentient
I've been aggressively asked the last few weeks if ChatGPT is sentient. Thinking about language geometrically explains why it is not.

Imagine a person who has grown up locked inside an isolation chamber and has never been allowed outside. Let’s call this person Bob.
The only thing Bob has inside his prison is millions of maps. Bob has a map of the world, of each town in the world, a map of what a leaf looks like, a map of what a cell of a leaf looks like. And he practices a lot at making these maps. He takes half a map at a time and then tries to draw the other half without seeing it. He does this over and over millions of times.
After a while you decide to test him out. You push a partially completed map under the door. Half the map is drawn. The other half the page is blank. Bob doesn’t recognize the specific town, but he can tell that this is a colonial town in New England and so he adds a town square and a small harbor. Bob pushes it back.
You’re impressed. It’s a realistic map of a town that doesn’t exist. However, Bob has never left his room. He’s never seen a river or a tree or a building. All he knows are squiggles on the map. And he knows the patterns that these squiggles come in. He doesn’t even know that the map represents real objects. But if Bob doesn’t actually know anything about the world, then what has he learned? Just like with ChatGPT, he’s learned manifolds.
Manifolds
Let’s take a circle. A circle exists in a 2-dimensional space, but you could specify every point on the circle with just one number: the degree of the circle. So we can say that this circle is a 1-dimensional manifold inside a 2-dimensional space. A sphere is a 3D object, but you can specify any point on the surface of the earth with just latitude and longitude, so the surface of a sphere is a 2D manifold in a 3D space.
Now let’s imagine a 7 x 7 grid of pixels, so 49 in total. Each pixel can be anywhere from white to grey to black and are represented as somewhere between 0 and 1, where 0 is a white pixel and 1 is black, and 0.5 is grey.
Now, if we draw a letter “T” in that grid, it will have 9 pixels filled in.

In machine learning you would represent this as a 49-dimensional space. In this space, each pixel is one dimension. That dimension ranges from 0 to 1 depending on how grey it is. A specific set of pixels, each at a particular shade of grey, is a point in this 49-dimensional space. If you haven’t studied linear algebra, a 49-dimensional space might sound baffling, but you don’t actually need to be able to imagine anything more than three dimensions. Just think of a 3-dimensional space in your mind, say 49 out loud, and you’re good to go.
Since one point in this space represents the 49 pixels at a specific set of greys, then one point represents one specific picture. That point represents that “T” above. But it would still be interpretable if you made one of the pixels lighter and changed it to grey, say a 0.7 or even 0.3. What you’re doing is moving that point in one direction in space. But you could move it in other ways too. Just like with the circle, where you describe each possible point of the circle with 1 dimension in a 2-dimensional space, you could do the same thing here and describe every possible “T” with 9 numbers. Meaning that you’re moving around a 9-dimensional manifold within this 49-dimensional space.
A neural net like ChatGPT learns that there are multiple manifolds within this space. Maybe one for an “X” another for a “T” another for a “Y”. When you give a generative model half an image, that’s giving it half the pixels, and it finds the manifold that those pixels are on and then fills in the other half. If you give it examples that aren’t on these manifolds, it doesn’t know what to do and fails in bizarre, but entertaining, ways.
What makes Transformers (the “T” in GPT stands for Transformer) so impressive is that they’re able to take text, convert it to these high dimensional spaces, and then find the nearest manifold and move around these manifolds. Transformers take your input, treat it as if it was half of an image, and then complete the other half. Like if you gave Bob half of a map and he drew in the other half.
Infinite Monkey Theorem
If Bob just splashed ink on the page there’s a chance that it could randomly make a shape that would complete the map in a realistic way. But it’s an infinitesimally small probability.
Imagine an old school television set, the kind with rabbit ears. Imagine that the signal is bad and it’s generating white noise. Each pixel is just randomly set to black or white. There’s no reason that the white noise couldn’t randomly generate pixels that show a tree. Or a face. Or even your own face.
But it’s very unlikely.
Geometrically, what you’re saying is that you’re hoping that in the n-dimensional space of images your television could show you (where n is the number of pixels) that you’re hoping that your television randomly selects a point that lies on the manifold of pictures of your face.
There’s that old line about how a million monkeys at a million keyboards would eventually write Shakespeare. But that’s not really true. If you filled the whole universe with billions of monkeys and them all typing from the Big Bang (14 billion years ago) until today, the probability that they would generate Hamlet is near zero.
ChatGPT probably could generate Hamlet, or something close. But that still doesn’t mean it’s sentient. Instead ChatGPT is just learning manifolds.
The Geometry of Language
So how do you get language into these manifolds? You can use machine learning to create spaces for words as well. These machine learning models put similar words near each other in these spaces.
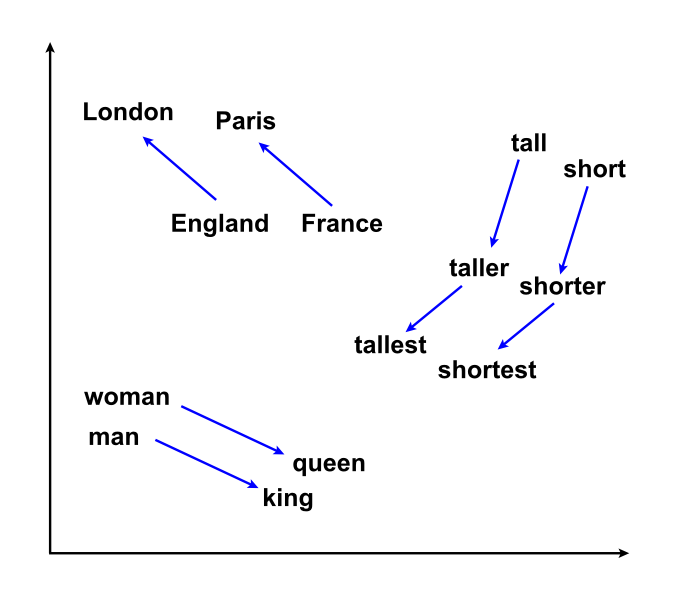
You can think of language as a kind of map of the world. Imagine wikipedia as a series of maps of the world. A map that explains what a dog is. What a forest is. Each one of these articles is a point in this wordspace. And ChatGPT has learned manifolds that connect them.
What would the geometry of sentience look like? I think that sentience would include (at a minimum) being able to at least see the world and then make maps based on it, as opposed to simply memorizing other maps without any awareness that they correspond to anything else. Imagine if a robot was able to see video of the world, interact with it, and then generate wikipedia (or Hamlet) based on what it’s observed.